




拙著「Java+MySQL+Tomcatで始めるWebアプリケーション構築入門」の53ページの記述について読者の方から質問がありました。このページではダブルクオート記号を"に置換するために次のようなコードを載せています。
(1) \bは、リテラルではバックスペースとして解釈され、正規表現では単語境界と解釈される。
(2) replaceAllの最初の引数では、\bはバックスペースのリテラルとして解釈され、\\bは正規表現の単語境界と解釈される。
なぜこのような複雑なことになっているのでしょうか。そこには、次のような事情がありました。
Javaの文字列(リテラル)は、まずエスケープシーケンスが該当の文字コードに変換されます。つまり、\bはバックスペースの文字コードに変換されます。replaceAllメソッドでは、この変換後の文字列が正規表現として解釈されます。\bは既に制御文字のコードに変換されているので、単語境界とは解釈されません。
文字列の中に\\bが含まれている場合、エスケープシーケンス\\が文字\に変換されます。その結果、rplaceAllメソッドに\bが渡され、単語境界として解釈されます。
そういったわけで、replaceAllメソッドで\を使う場合は、それがリテラルのエスケープシーケンスなのか、正規表現の記号なのかを区別して考える必要があるのです。ところが、冒頭に示したように\nの場合は\が1つでも2つでも同じ結果になります。これはなぜでしょう。
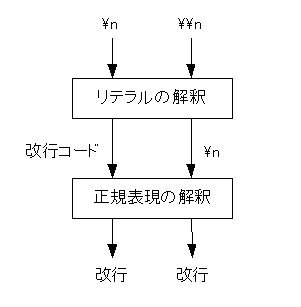
答えは簡単です。\nはリテラルのエスケープシーケンスと正規表現の両方で改行と解釈されるからです。\が1つの場合はリテラルのエスケープシーケンスとして解釈され、replaceAllメソッドには改行コードが渡されます。一方、\が2つの場合は、replaceAllメソッドに\nが渡され、そこで改行と解釈されるのです。
模式図
今までこれに気がついていなかったのは、入門書の著者としてはちょっと拙かったですね。お詫びして訂正します。
str.replaceAll("¥¥"",""");
このような行を含むコードをコンパイルしようとするとエラーになってしまいます。正しくは次のように\を重ねずに書く必要があります。 str.replaceAll("¥"",""");
これは明らかに私のミスですが、どうしてこのような間違いを犯したのか考えているうちに、面白いことに気が付きました。次のような場合は\が1つでも2つでもコンパイルは通り、改行コードは正しく<BR>タグに変換されるのです。 str.replaceAll("¥n","<BR>");
str.replaceAll("¥¥n","<BR>");
また、次のような場合は\を2つ重ねないとエラーになります。 str.replaceAll("¥¥)","カッコ閉じ");
いろいろ調べているうちに、StringクラスのreplaceAllメソッドは間接的にjava.util.regex.Patternクラスのcompileメソッドを呼び出していることが分かりました。そこで、APIドキュメントのjava.util.regex.Patternのページを見てみると、次のように書いてあります。たとえば、文字列リテラル "¥b" は、正規表現と解釈されると、バックスペース 1 文字とマッチされます。 しかし、"¥¥b" は単語境界とマッチされます。
この説明はちょっと分かりづらいのですが、つまり、こういうことです。(1) \bは、リテラルではバックスペースとして解釈され、正規表現では単語境界と解釈される。
(2) replaceAllの最初の引数では、\bはバックスペースのリテラルとして解釈され、\\bは正規表現の単語境界と解釈される。
なぜこのような複雑なことになっているのでしょうか。そこには、次のような事情がありました。
Javaの文字列(リテラル)は、まずエスケープシーケンスが該当の文字コードに変換されます。つまり、\bはバックスペースの文字コードに変換されます。replaceAllメソッドでは、この変換後の文字列が正規表現として解釈されます。\bは既に制御文字のコードに変換されているので、単語境界とは解釈されません。
文字列の中に\\bが含まれている場合、エスケープシーケンス\\が文字\に変換されます。その結果、rplaceAllメソッドに\bが渡され、単語境界として解釈されます。
そういったわけで、replaceAllメソッドで\を使う場合は、それがリテラルのエスケープシーケンスなのか、正規表現の記号なのかを区別して考える必要があるのです。ところが、冒頭に示したように\nの場合は\が1つでも2つでも同じ結果になります。これはなぜでしょう。
答えは簡単です。\nはリテラルのエスケープシーケンスと正規表現の両方で改行と解釈されるからです。\が1つの場合はリテラルのエスケープシーケンスとして解釈され、replaceAllメソッドには改行コードが渡されます。一方、\が2つの場合は、replaceAllメソッドに\nが渡され、そこで改行と解釈されるのです。
模式図
今までこれに気がついていなかったのは、入門書の著者としてはちょっと拙かったですね。お詫びして訂正します。
投稿:竹形 誠司[takegata]/2009年 02月 13日 16時 54分
/更新:2009年 02月 13日 17時 04分
